















Our team helps build smarter conversational AI solutions by creating annotated datasets that help train LLMs to understand diverse queries and master the nuances of the English language. This enables models to deliver natural, engaging, and accurate responses for every prompt.

Our team can review how accurately model-generated captions describe image or video inputs, rewriting captions as needed to improve accuracy, clarity, and brevity. We work closely with each client to define guidelines and align on quality rubrics to make the highly subjective work of evaluating captions as standardized as possible, reducing the chance of errors or hallucinations.

Our team helps model builders create high performing large language models while minimizing hallucinations. We systematically evaluate LLM outputs to identify preferred responses based on predefined criteria. This includes parameters such as relevancy to the prompt, factual accuracy, coherence, tone, and more.

Our team carefully reviews summarized outputs to ensure they are concise, coherent, and extract the key points of the original document. Annotators also evaluate for alignment in tone and style and ensure the model is following instructions, such as word count or formatting.

Our team will evaluate outputs from pre-trained models with RAG embeddings, assessing retrieval quality and relevance to ensure alignment with the prompt's intent. We use defined metrics to measure end-to-end performance and monitor for bias and accuracy issues.

Sama will evaluate your synthetic data, regardless of application — videos, image masking, custom backgrounds, etc. Sama helps evaluate model outputs for quality and visual realism. Any identified errors are flagged and used to retrain the model.
Sama’s model evaluation projects start with tailored consultations to understand your requirements for model performance. We’ll align on how you want your model to behave and set targets across a variety of dimensions.

Our team of Solutions engineers will collaborate with your team to connect to our platform and ensure a smooth flow of data. This can involve either connecting to your existing APIs or having custom integrations built specifically for your needs.

Our expert team meticulously crafts a plan to systematically test and evaluate model outputs to expose inaccuracies. We follow a robust evaluation process that involves a thorough examination of both prompts and the corresponding responses generated by the model. We will assess these elements based on predefined criteria, which may include factors like factual accuracy, coherence, consistency with the prompt's intent, and adherence to ethical guidelines.

As errors in model outputs are identified, our team will begin creating an additional training data set that can be used to finetune model performance. This new data consists of rewritten prompts and corresponding responses that address the specific mistakes made by the model.

When the project is complete, we follow a structured delivery process to ensure smooth integration with your model training pipeline. We offer flexible and customizable delivery formats, APIs, and the option for custom API integrations to support rapid development of models.

With over 15 years of industry experience, Sama’s data annotation and validation solutions help you build more accurate GenAI and LLMs—faster.
Our data experts will review your model’s responses for accuracy, identify and highlight any errors, and rewrite responses to improve model performance, combining workflow automation with our human-in-the-loop approach to ensure speed and quality.

Our team can assess how well your Gen AI model understands, interprets, and executes instructions. We’ll help you identify where your model doesn’t comply, including why a response was selected. Any issues are highlighted and flagged, making it easier and more efficient to fine-tune.

Sama’s highly trained team of experts can help you improve the quality and alignment of model outputs through feedback loops, RLHF, and more. With domain expertise across multiple industries and functions, we can analyze and rank model responses, indicate the rationale behind each choice, and highlight any issues within the outputs.

Sama can help you scale captioning for a variety of modalities. Our team of experts will describe the content of visual inputs, verify if the captions match, and rewrite captions as needed to retrain the model to reduce errors and hallucinations. Sama’s proprietary platform makes sampling easy and our collaborative workflows help reduce subjectivity and ambiguity from project kickoff.

With domain expertise across a variety of industries and functions, Sama’s dedicated team can create new prompts and responses based on your model goals. We can also rewrite responses, tailored to model capabilities and limitations, to augment existing training data. Our team can also employ chain of thought to provide clear rationale for chosen outputs.

When real training data is too difficult or not cost effective to obtain, our team can create synthetic data sets to help train your model, using a human-in-the-loop approach to ensure the highest level of quality. Our team will define objectives for your data, including a specific domain or other required parameters, and test outputs for quality and accuracy by comparing them against outputs from authentic data.
Our team is trained to provide comprehensive support across various modalities including text, image, and voice search applications. We help improve model accuracy and performance through a variety of solutions.
Our proactive approach minimizes delays while maintaining quality to help teams and models hit their milestones. All of our solutions are backed by SamaAssure™, the industry’s highest quality guarantee for Generative AI.
SamaIQ™ combines the expertise of the industry’s best specialists with deep industry knowledge and proprietary algorithms to deliver faster insights and reduce the likelihood of unwanted biases and other privacy or compliance vulnerabilities.
SamaHub™, our collaborative project space, is designed for enhanced communication. GenAI and LLM clients have access to collaboration workflows, self-service sampling and complete reporting to track their project’s progress.
We offer a variety of integration options, including APIs, CLIs, and webhooks that allow you to seamlessly connect our platform to your existing workflows. The Sama API is a powerful tool that allows you to programmatically query the status of projects, post new tasks to be done, receive results automatically, and more.
First batch client acceptance rate across 10B points per month
Get models to market 3x faster by eliminating delays, missed deadlines and excessive rework
Lives impacted to date thanks to our purpose-driven business model
2024 Customer Satisfaction (CSAT) score and an NPS of 64
Learn more about Sama's work with data curation
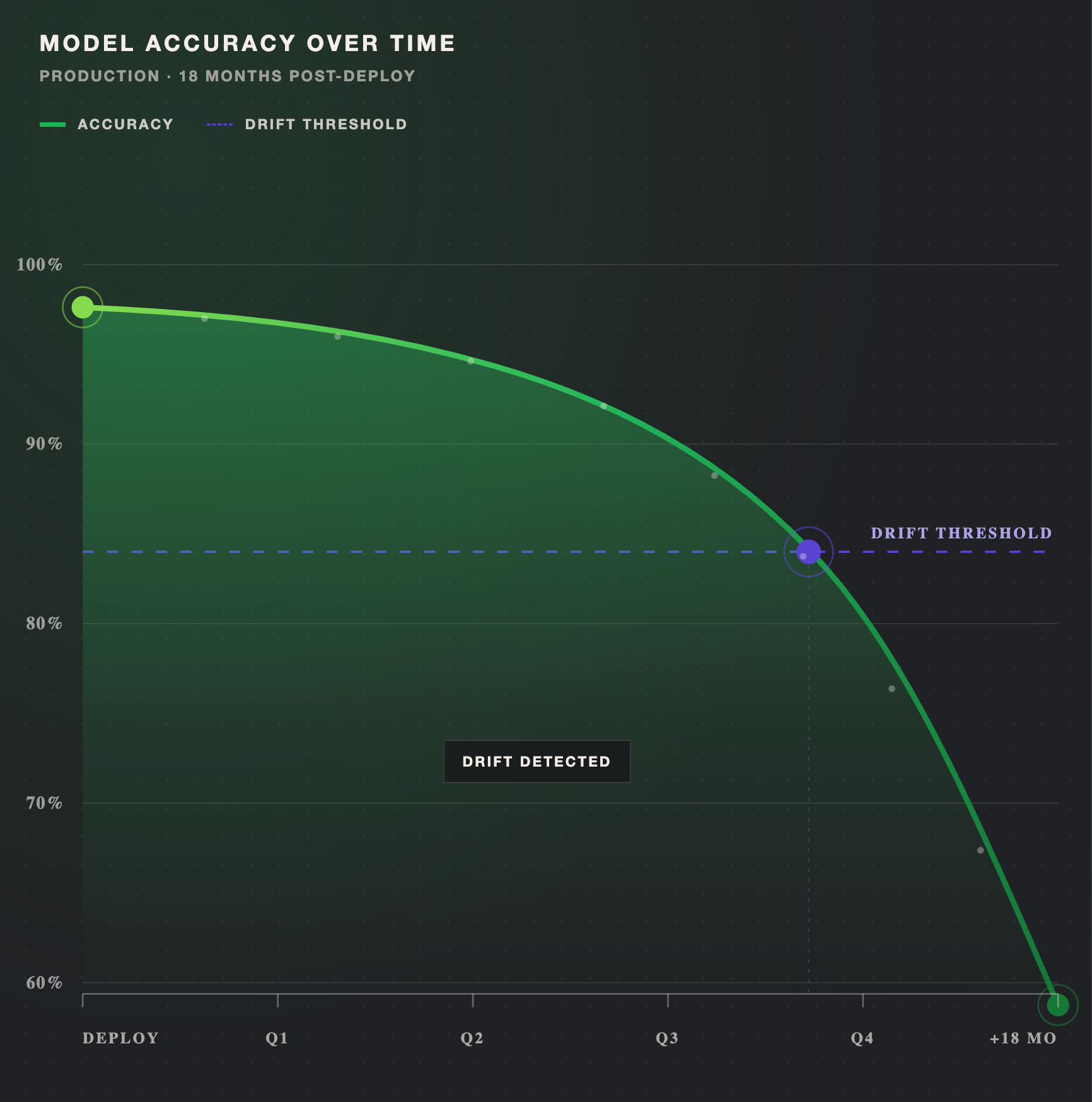
Model drift is the gradual loss of a production model's accuracy as real-world data shifts away from what it learned during training. This guide breaks down the three primary types of drift (data, concept, and label), what causes them, and how to detect drift early using performance monitoring and statistical tests. You'll also learn the prevention practices that keep retraining efficient and models accurate over time.
Sama provides ML Professionals and AI team Leads with an indispensable solution for Computer Vision data labeling.
